What Is a Serverless Database?

In the world of cloud databases, the word serverless is a misnomer. No application in the cloud operates without servers. Instead, serverless in the context of database management systems (DBMSs) – or in terms of any computing resource – refers to a service that provides the elements of computing or application development without requiring users to manage the software infrastructure for those elements.
In a serverless database, providers offer resources in a cloud-native, distributed fashion, spinning up and charging for just the database tools developers require, then shutting down.
The distributed, ephemeral nature of serverless DBMSs makes them a compelling alternative for developers looking for a relatively quick and easy approach to creating, testing, and running applications that are deployed intermittently.
Let’s dig in a bit deeper.
Why Serverless Now
Serverless databases have grown in popularity as data has proliferated and the pace of software development has picked up speed. In this environment, maintaining control of DBMS operations via on-premises servers takes time and expertise that could be better used in developing more innovative applications that use the mountains of data now available. Thus, instead of overseeing replication and updates as well as wrangling storage, busy DevOps teams can instead deploy serverless databases that require no infrastructure oversight on the customer’s part – while also allowing for cost savings by charging only for what’s used.
Serverless databases are also a logical outgrowth of the shift to cloud. The transition from deploying workloads on public clouds to relying on a serverless DBMS makes sense. The same theoretical construct of “function as a service” applies, as does usage-based pricing. So let's examine what's different about serverless.
Serverless Distinguished from Cloud DBMS
It's worth noting again that serverless DBMSs aren’t merely cloud-based offerings of database resources. The distinction is about elasticity: Instead of reserving cloud instances to create and run programs ahead of time, DevOps teams deploy serverless DBMSs on the fly, getting and paying for just the resources they use to develop, test, and run specific applications. Cloud resources do not need to be estimated and reserved beforehand, as they would in most public cloud services.
So serverless DBMSs relieve DevOps teams of the need to manage on-prem servers as well as the tasks of configuring and paying for estimated cloud resources. This can save significant operational and capital costs.
Requirements of Serverless DBMSs
Over time, it's become clear that a database designed to be serverless must meet several requirements. It must be:
Distributed. Serverless apps can’t reside in a single geographic location, but by definition must be able to deliver low latency and fast response times from multiple locations. This calls for a distributed DBMS design.
Scalable on demand. Sometimes referred to as elasticity, the ability to scale database resources up or down in response to user input is key to any serverless database.
Resilient. Serverless databases must be able to recover automatically from network failures without losing data or having to be reset.
Multi-tenant. Serverless databases must support many concurrent users without sacrificing performance.
Secure. Serverless databases must be secure. Since customers do not control the infrastructure, they rely on the provider to keep data safe. That provider must be able to meet service level agreements (SLAs) for security as well as performance.
Feature accurate billing. Consumption-based billing is at the heart of serverless databases, so a service must be able to track customer usage and deliver accurate billing of resources used.
Some Key Considerations for Serverless Customers
The serverless model has benefits for database developers. But there are a few things to consider in choosing a service.
As noted earlier, serverless DBMSs work best with apps that feature intermittent processing. An example might be updating a human resources database with new employee information – something that happens intermittently and is generally done quickly. Gauging the instances needed to support the app in a public cloud scenario can be daunting and, worst case, result in overestimating costly resources that go to waste. Using a serverless DBMS in this case can save money and time.
Conversely, database applications requiring extensive continuous processing may not be suitable for the serverless model. By running and consuming resources over long periods of time, an application such as an Internet of Things (IoT) monitoring system may quickly match or outstrip the comparable cost of running on prem or in a traditional cloud setup.
Serverless databases also present performance and security risks due to the multi-tenant nature of their delivery. When many users are tapping into the same resources, access can slow down. The separation of users must be secure to avoid any security loopholes. This is why it is so important that a provider be able to offer comprehensive SLAs.
Vendor lock-in has been cited as a further risk of serverless DBMSs. It is important to choose a service based on the specific languages, development environments, and other resources that fit an enterprise’s development patterns. For instance, some services are compatible with specific open-source tools, such as Apache Cassandra or Terraform. Some support more languages than others, and the level of support for apps on specific public cloud platforms is also a factor.
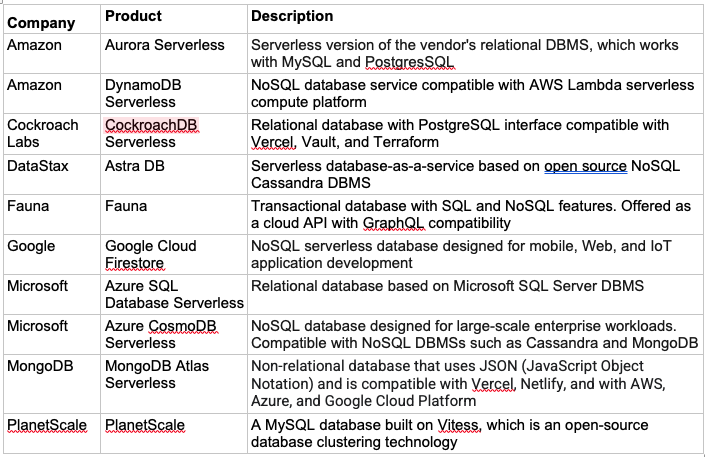
Some Examples
Serverless databases, and serverless versions of popular databases, are still new enough that many products remain in preview or in beta. Below is a partial list of some databases that are frequently mentioned in discussions of serverless development tools: